Newspeak differs from most programming languages in that it doesn’t provide a global namespace. And it differs from most imperative programming languages, because it has no static state.
I’ve spoken and written a fair amount about why the absence of static state is a good thing . What I haven’t discussed much is how you actually organize programs in this way. There have been a lot of questions along these lines. This post is an attempt to answer some of them.
Caveat: Some of the details here differ in the current prototype. Some of the features are still incomplete. What's described here is how things are supposed to work. We're not far from that.
First, let’s tackle the question of static state. It should be obvious: anything that you expected to put in a static variable goes in an instance variable of a module. What about singleton classes? How do I ensure that there’s only one instance? The easiest way is to initialize a read only slot of a module with an object literal. What happens if there are multiple instances of the module declaration? Well, each module has its own “singleton”. That’s exactly what happens with singleton classes in Java when they are defined by multiple class loaders.
What if your class defines some service process and you need to be really sure there’s only one in the entire system? First, in many cases you may find that the system in question is your subsystem, defined by your modules, and the answer above applies.
Now if you really mean “the entire system”, then you need to control that via some state in the platform object - through its links to the world’s state (e.g., the file system) or by having some registry in the platform object. Of course, not all code may see the true platform object, so it isn’t really global either; but it won’t matter.
Having no static state doesn’t preclude having a global namespace, as long as that namespace doesn’t contain any stateful objects. The original plan for Newspeak was to have a global namespace of pure values, structured as an inversion of the internet domain namespace. This would have been much like the convention for naming Java packages (except that the scopes of namespaces would nest properly, as you’d expect). It was the only idea from Java that I saw a use for in Newspeak. It’s a good idea, but it turns out to be unnecessary.
So, given no global namespace, what can I write at the top level? Remember, I can’t refer to any names, even things like Object or String that presumably exist in every implementation. This seems awkward. Not to worry - we won’t be writing SKI combinators or even plain old lambdas.
We might be able to write some literal expressions like 1 + 2, but that isn’t all that interesting, and isn’t even necessary. What we need to write are things that produce new kinds of objects, like classes.
Happily, we can write a a top level class declaration, with one caveat: A top level class declaration cannot declare a superclass explicitly since there is no way to name it, because there is no enclosing namespace. In that case, by special dispensation, the superclass will be the class Object provided by the underlying platform. Similar rules apply to object literals (which can be thought of as “anonymous classes done right”).
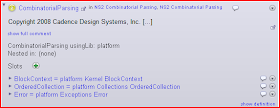
Ok, so now we can write a class, which can have other classes nested inside it, so it can be an entire library; and since there is no surrounding namespace, it is necessarily independent of any specifics of the environment - it is a module declaration. An example of such a module declaration would be the Newspeak AST
class NewspeakAST usingLib: platform { ....
... lots of nested AST classes ....
}
A similar class would be CombinatorialParsing library I’ve written about before.
There’s just one little problem. How do I use such a class? I gave it a name, but no one can refer to it, since there isn’t any surrounding namespace for the name to be bound!
Suppose I want to create a parser that builds an AST, using the two classes mentioned above. I need a grammar, which should be defined by a subclass of the parser library, and the parser class itself would in turn be a subclass of the grammar. Call these classes Grammar and Parser.
Since I can’t name the superclass of Grammar, I’ll just define it as a mixin, and worry about how to pair it with the superclass later.
class Grammar = { ....}
Likewise with Parser.
class Parser usingLib: platform astLib: ast = { ...}
That way I can define all the actual code required. The problem remaining is how to link all these pieces together.
If I actually had a namespace where I could refer to the pieces, I could write linking code like:
“confused”
main: platform {
MyGrammar = Grammar |> CombinatorialParsing usingLib: platform.
MyParser = Parser usingLib: platform astLib: NewspeakAST |> MyGrammar.
return:: MyParser parse: ‘a string in my language, perhaps?’
}
So how would I go about creating such a namespace? This is ultimately a question of tooling. Suppose my IDE lets me load class objects dynamically - say by reading in serialized class objects saved in files on disk. When it loads such a class object, it can reflect on it to find out its name, and store the class object in a slot of the same name in some new object it creates.
If I choose to load the classes, Grammar, Parser, CombinatorialParsing and NewspeakAST, I can create an object that is precisely the namespace I needed. I can then modify its class by adding the main: method listed above. This object is now an application, whose behavior is defined by its main: method. I can serialize this application object to disk.
Running my program then amounts to deserializing the object, and invoking its main: method with an object representing the current platform.
I’ve glossed over some crucial details here. We don’t really want to serialize the entire object, as it points to objects in our IDE, like Object, Class and a few others. These are standard, and we can cut off the object graph with symbolic links at these standard points, and have the deserializer hook up their equivalents on the destination.
Is using the IDE this way cheating? After all, it ultimately resorts to using the namespace of the underlying file system (or the network, or a global IDE namespace, depending where the IDE fetches class objects from). I think not. The truth is that this is what any language in the world does at some level. Whether we rely on a compiler that uses a CLASSPATH environment variable to define a set of local directories, or on the IDE, or on makefiles in a given directory to link separately compiled files, it is ultimately the same: some tool uses the operating system to find pieces of program.
We don’t have to use the IDE; we could use a preprocessor that understood directives that referred to classes in the file system instead. It could even use something as inane as CLASSPATH. Of course, I’m not really recommending that.
My key point is that the language needs nothing more than objects to serve as its namespaces.
Tuesday, December 09, 2008
Friday, December 05, 2008
Unidentified Foreign Objects (UFOs)
I recently found out that Newspeak’s basic foreign function interface (FFI), called Aliens, is being made available in Squeak (though that will require new VMs with the required primitives). Thanks to John McIntosh for doing this.
I should also thank Eliot Miranda for most of the original work on aliens, and Vassili Bykov, Peter Ahe and Bill Maddox for the rest. Also thanks to Lars Bak, whose work on the Strongtalk FFI inspired the VM level view of aliens; and to Dave Ungar, who was the first to understand that objects were all you needed on the language side of an FFI. Lastly, this post benefited immensely from conversations with Vassili.
So I figured I’d write a little bit about Aliens from a high level perspective. As usual, the ideas apply to programming languages in general.
In Smalltalk, there isn’t a standard FFI. Various dialects provide different solutions, with varying degrees of functionality, performance and ease of use. To be honest, they are usually a poor fit with the surrounding language and fairly awkward to use. This inhibits Smalltalk’s interoperability with the rest of the world. I’d argue that the absence of a good, standard FFI has cost the Smalltalk community dearly.
In Java, by contrast, native methods and JNI provide a standardized FFI. This mechanism is far from perfect, but at least there is a more or less standard solution.
What these and other systems have in common is support for a special construct (such as the native modifier for methods, or declarations like extern C, or the truly ugly ad hoc FFI syntax extensions used in various Smalltalks) for foreign functions.
Newspeak’s FFI was strongly influenced by the Strongtalk FFI; but unlike Strongtalk, Newspeak doesn’t have a special syntax for foreign calls. As Self showed many years ago, one doesn’t really need a special syntax for the FFI. The foreign functions, APIs, DLLs etc. can all be represented as objects. They just happen to be foreign objects.
The idea of a foreign object, which we call an alien, is at the foundation of the Newspeak FFI.
For starters, any decent language should be able to represent functions as values; and in an object-oriented language, these values are objects, accessed via a standard interface. Foreign functions are just a different implementation of that interface.
Another natural way to model a foreign function is as a method defined on a foreign object. For example, one can view an entire DLL as an object with a set of methods corresponding to the functions defined by the DLL. Better yet, we could represent an entire API as an object, independently of what DLLs actually defined it.
Aliens can be defined for different foreign languages; for example, while Alien is used to interface with C, we also have a class called ObjectiveCAlien that can be used to interface with ObjectiveC, which is the native language on MacOS X. C Aliens and ObjectiveC Aliens do not interfere with each other, and when/if we need to add Java Aliens or CLR Aliens we can do that as well.
The alien approach is also a good fit with security: one need not be concerned that code may bypass high level language safety guarantees by calling out to C; untrusted code can be prevented from doing that, simply by not providing any Alien library objects to it.
Newspeak’s C Alien implementation is fast, but also dangerous. An alien is basically a blob of memory. The user of an Alien is responsible for interpreting and accessing that data correctly. There is no checking being done for you.
Tangent: It's worth noting that the basic Alien layer may evolve further; for example, we aren't thrilled with the practice of subclassing Alien. It's not clear if the Alien class really needs to change, or just the pattern of using it.
On top of this foundation, safer and/or more convenient abstractions can be built. We have built objects that support not just methods corresponding to the functions of an API, but also methods that provide factories for the various datatypes used in the function’s signatures, including those defined by macros. These objects wrap the basic alien API, and help with error prone book keeping - converting between Newspeak types (e.g., Strings) and foreign types, freeing aliens after use etc.
At the moment, both the declarations of low level aliens and higher level APIs are constructed manually, which is tedious and error prone. We’ve been planning on a higher level tool called CSlick, which would allow you to specify a set of .h files and the requisite DLLs, and obtain an object that supports the desired functions automatically.
As a first approximation, you could think of CSlick as a function:
CSlick: List -> List -> ForeignAPI
The signature above is deliberately curried, because you may actually want to be able to specify just the header files, and later bind different DLLs to provide the actual functionality, just as a .h file can be associated with different .c files.
When this will happen is anyone’s guess right now; but Vassili has done this before (in the context of Lisp) and I’m sure he can do it again.
The resulting foreign API should incorporate the low level alien API, and, as much as possible, a higher level API as well.
The CSlick implementation will need to know how to parse C header files, and how to reflectively manufacture the low level code that actually invokes the C functions. Fortunately we have a strong parsing infrastructure, so that isn’t as daunting as it sounds.
When I’ve told people about CSlick, they often mention SWIG. However, I believe CSlick can be made substantially easier to use than SWIG. SWIG has to cope with multiple languages, each with a pre-existing story on how to do foreign calls. In contrast, we can integrate CSlick more tightly with the language. Ultimately, that should translate to a simpler model for the user.
The key take away is that objects are all you really need to interact with foreign programming languages. They are better than built in language constructs in terms of ease of use, security, and multiple language support. As usual, less is more.
I should also thank Eliot Miranda for most of the original work on aliens, and Vassili Bykov, Peter Ahe and Bill Maddox for the rest. Also thanks to Lars Bak, whose work on the Strongtalk FFI inspired the VM level view of aliens; and to Dave Ungar, who was the first to understand that objects were all you needed on the language side of an FFI. Lastly, this post benefited immensely from conversations with Vassili.
So I figured I’d write a little bit about Aliens from a high level perspective. As usual, the ideas apply to programming languages in general.
In Smalltalk, there isn’t a standard FFI. Various dialects provide different solutions, with varying degrees of functionality, performance and ease of use. To be honest, they are usually a poor fit with the surrounding language and fairly awkward to use. This inhibits Smalltalk’s interoperability with the rest of the world. I’d argue that the absence of a good, standard FFI has cost the Smalltalk community dearly.
In Java, by contrast, native methods and JNI provide a standardized FFI. This mechanism is far from perfect, but at least there is a more or less standard solution.
What these and other systems have in common is support for a special construct (such as the native modifier for methods, or declarations like extern C, or the truly ugly ad hoc FFI syntax extensions used in various Smalltalks) for foreign functions.
Newspeak’s FFI was strongly influenced by the Strongtalk FFI; but unlike Strongtalk, Newspeak doesn’t have a special syntax for foreign calls. As Self showed many years ago, one doesn’t really need a special syntax for the FFI. The foreign functions, APIs, DLLs etc. can all be represented as objects. They just happen to be foreign objects.
The idea of a foreign object, which we call an alien, is at the foundation of the Newspeak FFI.
For starters, any decent language should be able to represent functions as values; and in an object-oriented language, these values are objects, accessed via a standard interface. Foreign functions are just a different implementation of that interface.
Another natural way to model a foreign function is as a method defined on a foreign object. For example, one can view an entire DLL as an object with a set of methods corresponding to the functions defined by the DLL. Better yet, we could represent an entire API as an object, independently of what DLLs actually defined it.
Aliens can be defined for different foreign languages; for example, while Alien is used to interface with C, we also have a class called ObjectiveCAlien that can be used to interface with ObjectiveC, which is the native language on MacOS X. C Aliens and ObjectiveC Aliens do not interfere with each other, and when/if we need to add Java Aliens or CLR Aliens we can do that as well.
The alien approach is also a good fit with security: one need not be concerned that code may bypass high level language safety guarantees by calling out to C; untrusted code can be prevented from doing that, simply by not providing any Alien library objects to it.
Newspeak’s C Alien implementation is fast, but also dangerous. An alien is basically a blob of memory. The user of an Alien is responsible for interpreting and accessing that data correctly. There is no checking being done for you.
Tangent: It's worth noting that the basic Alien layer may evolve further; for example, we aren't thrilled with the practice of subclassing Alien. It's not clear if the Alien class really needs to change, or just the pattern of using it.
On top of this foundation, safer and/or more convenient abstractions can be built. We have built objects that support not just methods corresponding to the functions of an API, but also methods that provide factories for the various datatypes used in the function’s signatures, including those defined by macros. These objects wrap the basic alien API, and help with error prone book keeping - converting between Newspeak types (e.g., Strings) and foreign types, freeing aliens after use etc.
At the moment, both the declarations of low level aliens and higher level APIs are constructed manually, which is tedious and error prone. We’ve been planning on a higher level tool called CSlick, which would allow you to specify a set of .h files and the requisite DLLs, and obtain an object that supports the desired functions automatically.
As a first approximation, you could think of CSlick as a function:
CSlick: List
The signature above is deliberately curried, because you may actually want to be able to specify just the header files, and later bind different DLLs to provide the actual functionality, just as a .h file can be associated with different .c files.
When this will happen is anyone’s guess right now; but Vassili has done this before (in the context of Lisp) and I’m sure he can do it again.
The resulting foreign API should incorporate the low level alien API, and, as much as possible, a higher level API as well.
The CSlick implementation will need to know how to parse C header files, and how to reflectively manufacture the low level code that actually invokes the C functions. Fortunately we have a strong parsing infrastructure, so that isn’t as daunting as it sounds.
When I’ve told people about CSlick, they often mention SWIG. However, I believe CSlick can be made substantially easier to use than SWIG. SWIG has to cope with multiple languages, each with a pre-existing story on how to do foreign calls. In contrast, we can integrate CSlick more tightly with the language. Ultimately, that should translate to a simpler model for the user.
The key take away is that objects are all you really need to interact with foreign programming languages. They are better than built in language constructs in terms of ease of use, security, and multiple language support. As usual, less is more.
Monday, November 24, 2008
We have Good news, and we have Bad news
First, the good news. We will be releasing a Newspeak prototype in the first week of January 2009. This prototype is anything but finished, but it will have to do, because of the bad news (insert dramatic pause here).
What's the bad news? Well, funding for the Newspeak team is being discontinued in early January, another victim of the times.
We are currently seeking a new home for Newspeak, but it is by no means certain that such a thing can be found in the current economic climate. Perhaps I should take the Newspeak private jet to Washington and demand a bail-out - but alas, the jet is indisposed (when I call it all I get is message not understood)
We expect to keep pushing the Newspeak platform forward in any event; that said, there's a big difference between having several developers fully dedicated to a project, and the limited efforts people can make in their spare time. So the goal is to find support for the project soon - otherwise we'll all go get other jobs and progress on Newspeak will slow down accordingly.
Of course, once we put out the prototype, others can help fill in the blanks. I hope that will happen, irrespective of whether Newspeak gets further funding. I also plan to write up our work on Newspeak for academic publication.
Hopefully, this is only a temporary setback, and in it lies new opportunity: per aspera ad astra.
What's the bad news? Well, funding for the Newspeak team is being discontinued in early January, another victim of the times.
We are currently seeking a new home for Newspeak, but it is by no means certain that such a thing can be found in the current economic climate. Perhaps I should take the Newspeak private jet to Washington and demand a bail-out - but alas, the jet is indisposed (when I call it all I get is message not understood)
We expect to keep pushing the Newspeak platform forward in any event; that said, there's a big difference between having several developers fully dedicated to a project, and the limited efforts people can make in their spare time. So the goal is to find support for the project soon - otherwise we'll all go get other jobs and progress on Newspeak will slow down accordingly.
Of course, once we put out the prototype, others can help fill in the blanks. I hope that will happen, irrespective of whether Newspeak gets further funding. I also plan to write up our work on Newspeak for academic publication.
Hopefully, this is only a temporary setback, and in it lies new opportunity: per aspera ad astra.
Saturday, November 01, 2008
Dynamic IDEs for Dynamic Languages!
Dynamic languages are all the rage these days, and rightly so. Historically, most of the currently popular dynamic languages have had negligible IDE support (since they are scripting languages). More recently, we see a flurry of activity around IDE support for these languages. However, the mainstream IDEs are designed for, and implemented in, static languages. Consequently, even when dealing with a dynamic language, the dynamism stops when it comes to the IDE itself.
What do I mean by this? In an IDE written in a dynamic language (such as Smalltalk or Self or Lisp), the IDE code itself can be modified on the fly. This is a double edged sword, as I’ll explain shortly. I’ll start with the good edge.
Suppose you want to modify the IDE for some reason. It lacks a feature you need, or something is buggy. If it’s a proprietary system, you can file a bug with the vendor, and hope that they pay attention, so that in the next release, in a year or two, you’ll get the fix.
If the system is open source, you can just go ahead and implement the fix/feature. Now if that system is written in a mainstream, conventional language, you just need to recompile the compilation unit with the fix, and rebuild your system. Of course, in order to develop the fix, you had to load a project with the source for your IDE and probably go through several edit-compile-debug cycles. When it all worked, you replace your existing installation with your new build. I have the strange feeling that all this setting up the IDE as a project within itself, rebuilding and reinstalling could take quite a lot of time and effort.
In an IDE like Smalltalk (or Newspeak, or Self), the IDE source is always available from within itself. In such a system, if you change its source code, the change takes effect immediately. For example, the Newspeak class browser supports a pop up menu for methods, that lets you find references to the method and to the messages sent within it. In the screen shot below, the speech bubble on the right denotes this menu


However, the initial version did not support the same functionality for slots.
How do we fix this? Well, for starters, we need to find where the relevant source code is. How do you do this? The old fashioned way is to go on a trek through the source code trying to figure it out. What subdirectory should we start with? Which file should we open first? What should we grep for?
Fortunately, Newspeak makes it easy, as most IDE components have an Inspect Presenter menu item, that will open an object inspector on the actual presenter in question; a presenter on a presenter.
For example, if we want to find out how the references menu for methods works, we can look at a method like the one above. On the far right is a drop down menu:

This opens an object presenter, like this:

Toward the top, is a line marked class; it contains a hyperlink to the class of the object being inspected - the class ExpandableMethodPresenter. Now we know where the code that presents methods resides! If we click on the link, the Hopscotch browser will show us the class.
Having found the code that manages the presentation of methods, and the implementation of the references menu, we next want to find the code that presents slots, so we can modify it. We do the same thing again - invoke the Inspect Presenter menu item, but this time on a slot.
Once we’ve found the code and made the change, we can test it right away. Just hit refresh in the browser, and you’ll see the new reference bubble next to slots.
All of this is part of what Dan Ingalls, and Smalltalkers in general, mean when they say the system is alive. It’s the key property you seek in every system - its ability to respond to changes and mutate while running, which gives you the kind of interactivity you get in the real world with real objects. Live code in the IDE is the opposite of dead code - stuff written in files, which needs to be explicitly loaded into a runtime to do anything.
This all is very cool, but it also has a downside. Suppose you have a bug in your code, causing it to crash. You may be able to fix it in the debugger - but maybe the root of the problem is in another class. You need to browse it - but now, every time you try and browse a class, it crashes. You’ve shot yourself in the foot.
This is where you almost wish you were looking at dead code, by browsing files in an editor (or a conventional IDE). Fortunately, we know how to deal with this problem as well.
In this case, we want to manipulate the modified IDE from another, unmodified one, as a dynamic program. That way we still enjoy immediate feedback for our changes, while jkeeping our feet safe. Once it works, we want to be able to easily suck in the changes into the unmodifed version - without restarting, rebuilding, or going back to the big bang.
We haven’t implemented this yet - but much of it’s been done before, in the mid-90s, by Allen Wirfs-Brock in the FireWall project at ParcPlace. You do it using mirror based reflection.
One of the many things mirrors facilitate, is managing reflection in a distributed setting. Java’s JDI is an example of a mirror API was designed to do just that - though it has serious limitations because it has to work on a variety of JVMs. If you design the mirror API correctly, and build your IDE on it, the IDE can work almost identically on programs within the same process, in another process, or across the internet.
This ability to manage reflective changes to the IDE via a separate process is a luxury, which probably explains why it generally isn’t implemented, The reality is that shooting yourself in the foot is infrequent, and you can always recover (if only by saving your changes to a file before testing them). The benefits of liveness far outweigh the risks.
Nevertheless, in time, I expect to address this in the Newspeak IDE. In the meantime, it’s alive, even if support for death is lacking. Of course, the broader lesson is that IDEs especially, should be implemented using dynamic languages.
The above echoes my previous post from June, but I hope that the concrete examples are helpful. The liveness makes it easy to implement features like Inspect Presenter, which let you identify where to change the IDE, but even more critically, liveness allows you actually make the change and get instant feedback.
In closing, I want to emphasize that this is not an unprincipled approach. All of the above is possible because the IDE can reflect on itself. Self reference is at the heart of computing. It’s all about recursion. I find it strange that many theoretically oriented computer scientists, who can wax poetic about the Y combinator, eschew languages and systems that apply the same principles of self-application to themselves. I’m sure this is will change though; the good ideas win in the end.
What do I mean by this? In an IDE written in a dynamic language (such as Smalltalk or Self or Lisp), the IDE code itself can be modified on the fly. This is a double edged sword, as I’ll explain shortly. I’ll start with the good edge.
Suppose you want to modify the IDE for some reason. It lacks a feature you need, or something is buggy. If it’s a proprietary system, you can file a bug with the vendor, and hope that they pay attention, so that in the next release, in a year or two, you’ll get the fix.
If the system is open source, you can just go ahead and implement the fix/feature. Now if that system is written in a mainstream, conventional language, you just need to recompile the compilation unit with the fix, and rebuild your system. Of course, in order to develop the fix, you had to load a project with the source for your IDE and probably go through several edit-compile-debug cycles. When it all worked, you replace your existing installation with your new build. I have the strange feeling that all this setting up the IDE as a project within itself, rebuilding and reinstalling could take quite a lot of time and effort.
In an IDE like Smalltalk (or Newspeak, or Self), the IDE source is always available from within itself. In such a system, if you change its source code, the change takes effect immediately. For example, the Newspeak class browser supports a pop up menu for methods, that lets you find references to the method and to the messages sent within it. In the screen shot below, the speech bubble on the right denotes this menu

However, the initial version did not support the same functionality for slots.
How do we fix this? Well, for starters, we need to find where the relevant source code is. How do you do this? The old fashioned way is to go on a trek through the source code trying to figure it out. What subdirectory should we start with? Which file should we open first? What should we grep for?
Fortunately, Newspeak makes it easy, as most IDE components have an Inspect Presenter menu item, that will open an object inspector on the actual presenter in question; a presenter on a presenter.
For example, if we want to find out how the references menu for methods works, we can look at a method like the one above. On the far right is a drop down menu:

This opens an object presenter, like this:

Toward the top, is a line marked class; it contains a hyperlink to the class of the object being inspected - the class ExpandableMethodPresenter. Now we know where the code that presents methods resides! If we click on the link, the Hopscotch browser will show us the class.
Having found the code that manages the presentation of methods, and the implementation of the references menu, we next want to find the code that presents slots, so we can modify it. We do the same thing again - invoke the Inspect Presenter menu item, but this time on a slot.
Once we’ve found the code and made the change, we can test it right away. Just hit refresh in the browser, and you’ll see the new reference bubble next to slots.

All of this is part of what Dan Ingalls, and Smalltalkers in general, mean when they say the system is alive. It’s the key property you seek in every system - its ability to respond to changes and mutate while running, which gives you the kind of interactivity you get in the real world with real objects. Live code in the IDE is the opposite of dead code - stuff written in files, which needs to be explicitly loaded into a runtime to do anything.
This all is very cool, but it also has a downside. Suppose you have a bug in your code, causing it to crash. You may be able to fix it in the debugger - but maybe the root of the problem is in another class. You need to browse it - but now, every time you try and browse a class, it crashes. You’ve shot yourself in the foot.
This is where you almost wish you were looking at dead code, by browsing files in an editor (or a conventional IDE). Fortunately, we know how to deal with this problem as well.
In this case, we want to manipulate the modified IDE from another, unmodified one, as a dynamic program. That way we still enjoy immediate feedback for our changes, while jkeeping our feet safe. Once it works, we want to be able to easily suck in the changes into the unmodifed version - without restarting, rebuilding, or going back to the big bang.
We haven’t implemented this yet - but much of it’s been done before, in the mid-90s, by Allen Wirfs-Brock in the FireWall project at ParcPlace. You do it using mirror based reflection.
One of the many things mirrors facilitate, is managing reflection in a distributed setting. Java’s JDI is an example of a mirror API was designed to do just that - though it has serious limitations because it has to work on a variety of JVMs. If you design the mirror API correctly, and build your IDE on it, the IDE can work almost identically on programs within the same process, in another process, or across the internet.
This ability to manage reflective changes to the IDE via a separate process is a luxury, which probably explains why it generally isn’t implemented, The reality is that shooting yourself in the foot is infrequent, and you can always recover (if only by saving your changes to a file before testing them). The benefits of liveness far outweigh the risks.
Nevertheless, in time, I expect to address this in the Newspeak IDE. In the meantime, it’s alive, even if support for death is lacking. Of course, the broader lesson is that IDEs especially, should be implemented using dynamic languages.
The above echoes my previous post from June, but I hope that the concrete examples are helpful. The liveness makes it easy to implement features like Inspect Presenter, which let you identify where to change the IDE, but even more critically, liveness allows you actually make the change and get instant feedback.
In closing, I want to emphasize that this is not an unprincipled approach. All of the above is possible because the IDE can reflect on itself. Self reference is at the heart of computing. It’s all about recursion. I find it strange that many theoretically oriented computer scientists, who can wax poetic about the Y combinator, eschew languages and systems that apply the same principles of self-application to themselves. I’m sure this is will change though; the good ideas win in the end.
Saturday, September 20, 2008
Skinning Newspeak?
Whenever it comes to discussing language syntax, Parkinson’s law of triviality comes to mind.
Incidentally, the book is back in print! If you haven’t read it, check out this priceless classic.
Newspeak’s syntax currently resembles Smalltalk and Self. For the most part, this a fine thing, but I recognize that it can be a barrier to adoption. So, as we get closer to releasing Newspeak we may have to consider, with heavy heart, changes that could ease the learning curve.
One approach is the idea of syntactic skins. You keep the same abstract language underneath, but adjust its concrete syntax. In theory, you can have a skin that looks Smalltalkish, and one that looks Javanese, and another sort of like Visual Basic etc.
The whole idea of skins is closely related to Charles Simonyi’s notion of intentional programming. Cutting through the vapor, one of the few concrete things one can extract is the idea (not new or original with Simonyi) of an IDE that can present programs in a rich variety of skins, some of which are graphical. That, and support for defining DSLs for the domain experts to program in. This is all a fine thing, as long as you understand that’s all it is. This is still a pretty tall order.
In any case, Magnus Christerson is doing a superb job of making that vision a reality.
It is of course crucial that any program can be automatically displayed in any skin in the IDE. And designing skins requires thought, and is prone to abuse, which makes me hesitate.
Naming conventions that may make sense in one syntax may not really work in another, for example. Take maps (dictionaries in Smalltalk). In Smalltalk, the number of arguments to a method is encoded in the method name. So class Dictionary has a method called at:put:
aMap at: 3 put: 9.
In a javanese language, you’d tend to use a different name, say, put
aMap.put(3, 9);
However, with skins, you need to either use the very same name
aMap.at:put:(3, 9);
which looks weird and may even conflict with other parts of the syntax, or have some automated transformation
aMap.atPut(3, 9);
All of which looks odd and may have issues (after all at:Put: would be a distinct, legal Newspeak method name which would also map to atPut). And what happens if you start writing your code in the javanese syntax? How do I map put into a 2 argument Newspeak method name? p:ut:? pu:t:? Maybe in this case, it takes a single tuple as its argument:
aMap put: {3. 9}.
There may be a creative way out; Mads Torgersen once suggested a syntax like
aMap.at(3) put(9)
Or maybe we map all names into ratHole.
The standard procedure call syntax also has more substantial difficulties. Without a typechecker, it’s hard to get the number of arguments right. The Smalltalk keyword syntax, while unfamiliar to many, has a huge advantage in a dynamically typed setting - no arity errors (if you’ve written any javascript, you probably know what I mean).
In addition, the Smalltalk keyword notation is really nice for defining embedded DSLs, as Vassili notes in a recent post. This is a point that I want to expand upon at some future time.
So I’m pretty sure that regardless of whether we use skins or not, we’ll retain the keyword message send syntax across all skins. It’s just a good idea for this sort of language.
There are syntactic elements that are easy to tweak so that they are more familiar to a wider audience. In some cases, there are standard syntactic conventions that work well, and we can just adopt them. For example, using curly braces as delimiters for class and method bodies (and also closures), or using return: instead of ^. If these were the only issues, one might not really consider skins, since the differences are minor. The current draft spec mentions some of these.
Skins may be most valuable for issues in between the two extremes cited above. One of the most obvious is operator precedence. People have been taught a set of precedences in elementary school, and most have never recovered. Programmers have also learned C or something similar, they have even more expectations in this regard.
Newspeak, like Smalltalk, gives all binary operators equal precedence, evaluating them in order from left to right.
5 + 4 * 3 evaluates to 27 in Smalltalk, not to 17.
Now I have never, ever had a bug due to this, but many people get all worked up over this issue. Why not just give in, and follow standard precedence rules? Well, there is the question of whose rules - C, Java, Perl? What about operators those languages don’t have (ok, so Perl probably has all operators in the known universe and some to spare)?
Another issue is that Newspeak is designed to let you embed domain specific languages as libraries. Then the standard choices don’t always make sense. Allow people to set precedence explicitly you say? This is problematic. Newspeak aims to stay simple. This is a matter of taste and judgement. If you like an endless supply of bells and whistles, look elsewhere.
Skins might give us an out. Some skins would dictate the precedence of popular operators (leaving the rest left-to-right, as in Scala for example). This means your DSL may look odd in another skin, but maybe that’s tolerable.
Once you have skins, you can also address issues that otherwise aren’t worth dealing with - like dots. If you really feel the need to write aList.get instead of aList get, a suitable skin could be made available.
It looks like language skins can be used to bridge over minor syntactic differences, but not much more. On the other hand, if you don’t have skins, you have a better chance of establishing a shared lingua franca amongst a programming community.
Overall, my sense is that such skins are more trouble than they’re worth.
Incidentally, the book is back in print! If you haven’t read it, check out this priceless classic.
Newspeak’s syntax currently resembles Smalltalk and Self. For the most part, this a fine thing, but I recognize that it can be a barrier to adoption. So, as we get closer to releasing Newspeak we may have to consider, with heavy heart, changes that could ease the learning curve.
One approach is the idea of syntactic skins. You keep the same abstract language underneath, but adjust its concrete syntax. In theory, you can have a skin that looks Smalltalkish, and one that looks Javanese, and another sort of like Visual Basic etc.
The whole idea of skins is closely related to Charles Simonyi’s notion of intentional programming. Cutting through the vapor, one of the few concrete things one can extract is the idea (not new or original with Simonyi) of an IDE that can present programs in a rich variety of skins, some of which are graphical. That, and support for defining DSLs for the domain experts to program in. This is all a fine thing, as long as you understand that’s all it is. This is still a pretty tall order.
In any case, Magnus Christerson is doing a superb job of making that vision a reality.
It is of course crucial that any program can be automatically displayed in any skin in the IDE. And designing skins requires thought, and is prone to abuse, which makes me hesitate.
Naming conventions that may make sense in one syntax may not really work in another, for example. Take maps (dictionaries in Smalltalk). In Smalltalk, the number of arguments to a method is encoded in the method name. So class Dictionary has a method called at:put:
aMap at: 3 put: 9.
In a javanese language, you’d tend to use a different name, say, put
aMap.put(3, 9);
However, with skins, you need to either use the very same name
aMap.at:put:(3, 9);
which looks weird and may even conflict with other parts of the syntax, or have some automated transformation
aMap.atPut(3, 9);
All of which looks odd and may have issues (after all at:Put: would be a distinct, legal Newspeak method name which would also map to atPut). And what happens if you start writing your code in the javanese syntax? How do I map put into a 2 argument Newspeak method name? p:ut:? pu:t:? Maybe in this case, it takes a single tuple as its argument:
aMap put: {3. 9}.
There may be a creative way out; Mads Torgersen once suggested a syntax like
aMap.at(3) put(9)
Or maybe we map all names into ratHole.
The standard procedure call syntax also has more substantial difficulties. Without a typechecker, it’s hard to get the number of arguments right. The Smalltalk keyword syntax, while unfamiliar to many, has a huge advantage in a dynamically typed setting - no arity errors (if you’ve written any javascript, you probably know what I mean).
In addition, the Smalltalk keyword notation is really nice for defining embedded DSLs, as Vassili notes in a recent post. This is a point that I want to expand upon at some future time.
So I’m pretty sure that regardless of whether we use skins or not, we’ll retain the keyword message send syntax across all skins. It’s just a good idea for this sort of language.
There are syntactic elements that are easy to tweak so that they are more familiar to a wider audience. In some cases, there are standard syntactic conventions that work well, and we can just adopt them. For example, using curly braces as delimiters for class and method bodies (and also closures), or using return: instead of ^. If these were the only issues, one might not really consider skins, since the differences are minor. The current draft spec mentions some of these.
Skins may be most valuable for issues in between the two extremes cited above. One of the most obvious is operator precedence. People have been taught a set of precedences in elementary school, and most have never recovered. Programmers have also learned C or something similar, they have even more expectations in this regard.
Newspeak, like Smalltalk, gives all binary operators equal precedence, evaluating them in order from left to right.
5 + 4 * 3 evaluates to 27 in Smalltalk, not to 17.
Now I have never, ever had a bug due to this, but many people get all worked up over this issue. Why not just give in, and follow standard precedence rules? Well, there is the question of whose rules - C, Java, Perl? What about operators those languages don’t have (ok, so Perl probably has all operators in the known universe and some to spare)?
Another issue is that Newspeak is designed to let you embed domain specific languages as libraries. Then the standard choices don’t always make sense. Allow people to set precedence explicitly you say? This is problematic. Newspeak aims to stay simple. This is a matter of taste and judgement. If you like an endless supply of bells and whistles, look elsewhere.
Skins might give us an out. Some skins would dictate the precedence of popular operators (leaving the rest left-to-right, as in Scala for example). This means your DSL may look odd in another skin, but maybe that’s tolerable.
Once you have skins, you can also address issues that otherwise aren’t worth dealing with - like dots. If you really feel the need to write aList.get instead of aList get, a suitable skin could be made available.
It looks like language skins can be used to bridge over minor syntactic differences, but not much more. On the other hand, if you don’t have skins, you have a better chance of establishing a shared lingua franca amongst a programming community.
Overall, my sense is that such skins are more trouble than they’re worth.
Sunday, August 31, 2008
Foreign functions, VM primitives and Mirrors
An issue that crops up in systems based on virtual machine is: what are the primitives provided by the VM and how are they represented?
One answer would be that those are simply the instructions constituting the virtual machine language (often referred to as byte codes). However, one typically finds that there are some operations that do not fit this mold. An example would be the defineClass() method, whose job is to take a class definition in JVML (Java Virtual Machine Language) and install it into the running JVM. Another would be the getClass() method that every Java object supports.
These operations cannot be expressed directly by the high level programming languages running on the VM, and no machine instruction is provided for them either. Instead, the VM provides a procedural interface. So while the Java platform exposes getClass(), defineClass() and the like, behind the scenes these Java methods invoke a VM primitive to do their job.
Why aren’t primitives supported by their own, dedicated virtual machine language instructions? One reason is there are typically too many of them, and giving each an instruction might disrupt the instruction set architecture (because you might need too many bits for opcodes, for example). It’s also useful to have an open ended set of primitives, rather than hardwiring them in the instruction set.
You won’t find much discussion of VM primitives in the Java world. Java provides no distinct mechanism for calling VM primitives. Instead, primitives are treated as native methods (aka foreign functions) and called using that mechanism. Indeed, in Java there is no distinction between a foreign function and a VM primitive: a VM primitive is foreign function implemented by the VM.
On its face, this seems reasonable. The JVM is typically implemented in a foreign language (usually C or C++) and it can expose any desired primitives as C functions that can then be accessed as native methods. It is very tempting to use one common mechanism for both purposes.
One of the goals of this post is to explain why this is wrong, and why foreign functions and VM primitives differ and should be treated differently.
Curiously, while Smalltalk defines no standardized FFI (Foreign Function Interface), the original specification defines a standard set of VM primitives. Part of the reason is historical: Smalltalk was in a sense the native language on the systems where it originated. Hence there was no need for an FFI (just as no one ever talks about an FFI in C), and hence primitives could not be defined in terms of an FFI and had to be thought of distinctly.
However, the distinction is useful regardless. Calling a foreign function requires marshaling of data crossing the interface. This raises issues of different data formats, calling conventions, garbage collection etc. Calling a VM primitive is much simpler: the VM knows all there is to know about the management of data passed between it and the higher level language.
The set of primitives is moreover small and under the control of the VM implementor. The set of foreign functions is unbounded and needs to be extended routinely by application programmers. So the two have different usability requirements.
Finally, the primitives may not be written in a foreign language at all, but in the same language in a separate layer.
So, I’d argue that in general one needs both an FFI and a notion of VM primitives (as in, to take a random example, Strongtalk). Moreover, I would base an FFI on VM primitives rather than the other way around. That is, a foreign call is implemented by a particular primitive (call-foreign-function).
Consider that native methods in Java are implemented with VM support; the JVM’s method representation marks native methods specially, and the method invocation instructions handle native calls accordingly.
The Smalltalk blue book’s handling of primitives is similar; primitive methods are marked specially and handled as needed by the method invocation (send) instructions.
It might be good to have one instruction, invokeprimitive, dedicated to calling primitives. Each primitive would have an identifying code, and one assumes that the set of primitives would never exceed some predetermined size (8 bits?). That would keep the control of the VM entirely within the instruction set.
It is good to have a standardized set of VM primitives, as Smalltalk-80 did. It makes the interface between the VM and built in libraries cleaner, so these libraries can be portable. We discussed doing this for the JVM about nine or ten years ago, but it never went anywhere.
If primitives aren’t just FFI calls, how does one invoke them at the language level? Smalltalk has a special syntax for them, but I believe this is a mistake. In Newspeak, we view a primitive call as a message send to the VM. So it is natural to reify the VM via a VM mirror that supports messages corresponding to all the primitives.
A nice thing abut using a mirror in this way, is that access to primitives is now controlled by a capability (the VM mirror), so the standard object-capability architecture handles access to primitives just like anything else.
To get this to really work reliably, the low level mirror system must prohibit installation of primitive methods by compilers etc.
Another desirable propery of this scheme is that you can emulate the primitives in a regular object for purposes of testing, profiling or whatever. It's all a natural outgrowth of using objects and message passing throughout.
One answer would be that those are simply the instructions constituting the virtual machine language (often referred to as byte codes). However, one typically finds that there are some operations that do not fit this mold. An example would be the defineClass() method, whose job is to take a class definition in JVML (Java Virtual Machine Language) and install it into the running JVM. Another would be the getClass() method that every Java object supports.
These operations cannot be expressed directly by the high level programming languages running on the VM, and no machine instruction is provided for them either. Instead, the VM provides a procedural interface. So while the Java platform exposes getClass(), defineClass() and the like, behind the scenes these Java methods invoke a VM primitive to do their job.
Why aren’t primitives supported by their own, dedicated virtual machine language instructions? One reason is there are typically too many of them, and giving each an instruction might disrupt the instruction set architecture (because you might need too many bits for opcodes, for example). It’s also useful to have an open ended set of primitives, rather than hardwiring them in the instruction set.
You won’t find much discussion of VM primitives in the Java world. Java provides no distinct mechanism for calling VM primitives. Instead, primitives are treated as native methods (aka foreign functions) and called using that mechanism. Indeed, in Java there is no distinction between a foreign function and a VM primitive: a VM primitive is foreign function implemented by the VM.
On its face, this seems reasonable. The JVM is typically implemented in a foreign language (usually C or C++) and it can expose any desired primitives as C functions that can then be accessed as native methods. It is very tempting to use one common mechanism for both purposes.
One of the goals of this post is to explain why this is wrong, and why foreign functions and VM primitives differ and should be treated differently.
Curiously, while Smalltalk defines no standardized FFI (Foreign Function Interface), the original specification defines a standard set of VM primitives. Part of the reason is historical: Smalltalk was in a sense the native language on the systems where it originated. Hence there was no need for an FFI (just as no one ever talks about an FFI in C), and hence primitives could not be defined in terms of an FFI and had to be thought of distinctly.
However, the distinction is useful regardless. Calling a foreign function requires marshaling of data crossing the interface. This raises issues of different data formats, calling conventions, garbage collection etc. Calling a VM primitive is much simpler: the VM knows all there is to know about the management of data passed between it and the higher level language.
The set of primitives is moreover small and under the control of the VM implementor. The set of foreign functions is unbounded and needs to be extended routinely by application programmers. So the two have different usability requirements.
Finally, the primitives may not be written in a foreign language at all, but in the same language in a separate layer.
So, I’d argue that in general one needs both an FFI and a notion of VM primitives (as in, to take a random example, Strongtalk). Moreover, I would base an FFI on VM primitives rather than the other way around. That is, a foreign call is implemented by a particular primitive (call-foreign-function).
Consider that native methods in Java are implemented with VM support; the JVM’s method representation marks native methods specially, and the method invocation instructions handle native calls accordingly.
The Smalltalk blue book’s handling of primitives is similar; primitive methods are marked specially and handled as needed by the method invocation (send) instructions.
It might be good to have one instruction, invokeprimitive, dedicated to calling primitives. Each primitive would have an identifying code, and one assumes that the set of primitives would never exceed some predetermined size (8 bits?). That would keep the control of the VM entirely within the instruction set.
It is good to have a standardized set of VM primitives, as Smalltalk-80 did. It makes the interface between the VM and built in libraries cleaner, so these libraries can be portable. We discussed doing this for the JVM about nine or ten years ago, but it never went anywhere.
If primitives aren’t just FFI calls, how does one invoke them at the language level? Smalltalk has a special syntax for them, but I believe this is a mistake. In Newspeak, we view a primitive call as a message send to the VM. So it is natural to reify the VM via a VM mirror that supports messages corresponding to all the primitives.
A nice thing abut using a mirror in this way, is that access to primitives is now controlled by a capability (the VM mirror), so the standard object-capability architecture handles access to primitives just like anything else.
To get this to really work reliably, the low level mirror system must prohibit installation of primitive methods by compilers etc.
Another desirable propery of this scheme is that you can emulate the primitives in a regular object for purposes of testing, profiling or whatever. It's all a natural outgrowth of using objects and message passing throughout.
Sunday, July 27, 2008
Invisible Video
A quick update; several people have told me that the Smalltalk Solutions video of the Hopscotch demo is unhelpful, since you can't see the screen. I should have watched it before linking to it; I apologize. Since I was in the room during the presentation, I didn't think to watch it again. My bad. I've taken the link down. We'll produce a viewable demo for download and post it in th enear future. Again, apologies to to anyone who spent time downloading/watching the unwatchable.
Saturday, July 26, 2008
Debugging Visual Metaphors
My previous post commented on the unsatisfactory state of mainstream IDEs. Continuing with this theme, I want to focus on one of my long term pet peeves - debugger UIs.
Donald Norman, in his book The Design of Everyday Things, makes the point that truly good designs are easy to use, because they make it intuitive how they should be used - in his words, they afford a usage pattern.
How do you describe the state of a running program on a whiteboard? You draw the stack. So it seems to me that a stack is the natural visual metaphor for a debugger. Here is a screen shot of our new Hopscotch-based debugger, which will soon replace the Squeak debugger in the Newspeak IDE.

You can see that the debugger looks like a stack trace. Every entry in the stack trace can be expanded into a presenter that shows that stack frame - including the source code for the method in question, and a view of the state of the frame - the receiver, the variables in the activation, the top of the evaluation stack for expressions (i.e., the last value computed).
Of course, this isn’t my idea. It’s another one of those great ideas from Self, as evidenced in this screenshot:

we already stole the idea from Self once before, in Strongtalk, as shown here.

One of the nice properties of the stack oriented view is that you can view multiple stack frames at once, so you can see and reason about a series of calls, much as you would at your whiteboard.
In contrast, most IDEs (even Smalltalk IDEs) show a multi-pane view, with one pane showing the source for the current method (in its file, naturally), one pane showing the state of the current frame, and one showing the stack trace.

You can’t easily see the state of the caller of the current method, or its code, while simultaneously looking at the current method (or another activation in the call chain). And if you modify the current method’s code (assuming you can do that at all), you’re likely locked into a mode, and can’t see the other frames unless you save or cancel your changes.
Hopscotch GUIs are inherently non-modal - so you can modify any one of the methods you’re viewing, and then link to another page to view, say, the complete class declaration, all without opening another window and without having to save or lose your work.
The fact that one rarely needs more than one window is one of the things I really like about Hopscotch. There’s no need for a docking bar, or tabs for that matter. Tabs are popular these days, but they don’t scale: they occupy valuable screen real estate, and beyond half a dozen or so become disorienting and unmanageable.
Hopscotch does better than the mainstream, and better than previous efforts like Strongtalk or Self, partly because of its navigation model, and partly because of the inherent compositionality of tools built with it. The fact that I can move from the debugger to the class browser in the same window did not require special planning - it’s inherent in the way Hopscotch based tools behave - they can be composed by means of a set of combinators. Compositionality is one of the most crucial, and most often overlooked, properties in software design; it’s what sets Hopscotch apart.
You can find out more about Hopscotch in this paper and on Vassili ‘s blog.
The design of debugger UIs is one example of something that needs to change in modern IDEs. There are others of course. Many are related to the basic problems of modality, navigation and proliferation of panes/windows noted above. Overall, your typical IDE UI is too much like the control panel of a B-52 bomber or an Apollo space capsule: a mind boggling array of switches, gauges, controls and wizards that interact with each other in myriad and confusing ways. This is neither necessary nor desirable. Like explicit memory management and primitive types, in time we will progress beyond these.
Donald Norman, in his book The Design of Everyday Things, makes the point that truly good designs are easy to use, because they make it intuitive how they should be used - in his words, they afford a usage pattern.
How do you describe the state of a running program on a whiteboard? You draw the stack. So it seems to me that a stack is the natural visual metaphor for a debugger. Here is a screen shot of our new Hopscotch-based debugger, which will soon replace the Squeak debugger in the Newspeak IDE.
You can see that the debugger looks like a stack trace. Every entry in the stack trace can be expanded into a presenter that shows that stack frame - including the source code for the method in question, and a view of the state of the frame - the receiver, the variables in the activation, the top of the evaluation stack for expressions (i.e., the last value computed).
Of course, this isn’t my idea. It’s another one of those great ideas from Self, as evidenced in this screenshot:
we already stole the idea from Self once before, in Strongtalk, as shown here.
One of the nice properties of the stack oriented view is that you can view multiple stack frames at once, so you can see and reason about a series of calls, much as you would at your whiteboard.
In contrast, most IDEs (even Smalltalk IDEs) show a multi-pane view, with one pane showing the source for the current method (in its file, naturally), one pane showing the state of the current frame, and one showing the stack trace.
You can’t easily see the state of the caller of the current method, or its code, while simultaneously looking at the current method (or another activation in the call chain). And if you modify the current method’s code (assuming you can do that at all), you’re likely locked into a mode, and can’t see the other frames unless you save or cancel your changes.
Hopscotch GUIs are inherently non-modal - so you can modify any one of the methods you’re viewing, and then link to another page to view, say, the complete class declaration, all without opening another window and without having to save or lose your work.
The fact that one rarely needs more than one window is one of the things I really like about Hopscotch. There’s no need for a docking bar, or tabs for that matter. Tabs are popular these days, but they don’t scale: they occupy valuable screen real estate, and beyond half a dozen or so become disorienting and unmanageable.
Hopscotch does better than the mainstream, and better than previous efforts like Strongtalk or Self, partly because of its navigation model, and partly because of the inherent compositionality of tools built with it. The fact that I can move from the debugger to the class browser in the same window did not require special planning - it’s inherent in the way Hopscotch based tools behave - they can be composed by means of a set of combinators. Compositionality is one of the most crucial, and most often overlooked, properties in software design; it’s what sets Hopscotch apart.
You can find out more about Hopscotch in this paper and on Vassili ‘s blog.
The design of debugger UIs is one example of something that needs to change in modern IDEs. There are others of course. Many are related to the basic problems of modality, navigation and proliferation of panes/windows noted above. Overall, your typical IDE UI is too much like the control panel of a B-52 bomber or an Apollo space capsule: a mind boggling array of switches, gauges, controls and wizards that interact with each other in myriad and confusing ways. This is neither necessary nor desirable. Like explicit memory management and primitive types, in time we will progress beyond these.
{kind=link}
Saturday, June 07, 2008
Incremental Development Environments
Back in 1997, when I started working at Sun, I did not expect to do much programming language design. After all, Java was completely specified in the original JLS, or so it was thought.
What I actually expected to do was to work on a Java IDE. Given my Smalltalk background, I was of course very much aware of how valuable a good IDE is for programmers. The Java IDE I had in mind never materialized. Management at the time thought this was an issue to be left to other vendors. If this seems a little strange today - well, it seemed strange back then too. In any case, the Java world has since learned that IDEs are very important and strategic.
That said, todays Java IDEs are still very different from what I envisioned based on my Smalltalk background.
Java IDEs have yet to fully embrace the idea of incremental development. Look in any such system, and you’ll find a button or menu labeled Build. The underlying idea is that a program is assembled from scratch every time you change it.
Of course, that is how the real world works, right? You find a broken window on the Empire State building, so you tear it down and rebuild it with the fixed window. If you're clever, you might be able to do it pretty fast. Ultimately, it doesn't scale.
The build button comes along with an obsession with files. In C and its ilk, the notion of files is part of the language, because of #include. Fortunately, Java did away with that legacy. Java programmers can think in terms of packages, independent of their representation on disk. Why spend time worrying about class paths and directory structures? What do these have to do with the structure of your program and the problem you’re trying to solve?
The only point where files are useful in this context is as a medium for sharing source code or distributing binary code. Files are genuinely useful for those purposes, and Smalltalk IDEs have generally gone overboard in the opposite direction; but I digress.
A consequence of the file/build oriented view is that the smallest unit of incremental change is the file - something that is often too big (if you ever notice the time it takes to compile a change, that’s too long) and moreover, not even a concept in the language.
More fundamentally, what’s being changed is a static, external representation of the program code; there is no support for changing the live process derived from the code so that it matches up with the code that describes it. It’s like having a set of blueprints for a building (the code in the file) which doesn’t match the building (the process generated from the code).
For example, once you add an instance variable to a class, what happens to all the existing instances on the heap? In Smalltalk, they all have the new instance variable. In Java - well, nothing happens.
In general, any change you make to the code should be reflected immediately in the entire environment. This implies a very powerful form of fix-and-continue debugging (I note in amazement that after all these years, Eclipse still doesn’t support even the most basic form of fix-and-continue).
All this is of course a very tall order for a language with a mandatory static type system.
I’m not aware of a JVM implementation that can begin to deal with class schema changes (that is, changing the shapes of objects because their class has lost or acquired fields). It’s not impossible, but it is hard.
Consider that removing a field requires invalidating any code that refers to it. In a language where fields are private, the amount of code to invalidate is nicely bounded to the class (good design decisions tend to simplify life). Public fields, apart from their nasty software engineering properties, add complexity to the underlying system.
This isn’t just a headache for the IDE. The VM has to provide support for changing the classes of existing instances. However, in the absence of VM support there all kinds of tricks one can play. If you compile all code yourself, you can ensure that no one accesses fields directly - everything goes through accessors. You can even rewrite imported binaries. With enough effort, I believe you can make it all work on an existing JVM with good JVMDI support.
Changing code in a method is supported by JVMDI (well, the JVMDI spec allows for supporting schema changes as well - it’s just that it isn’t required and no one ever implemented it). However, what happens if you change the signature of a method? Any number of existing callers may be invalid due to type errors. The IDE needs to tell you about this pretty much instantaneously, invalidating all these callers. Most of this worked in Trellis/Owl back in the late 80s. The presence of the byte code verifier means that this applies to binary code as well.
Achieving true incremental development is very hard. Still, given the amount of people working on Java, you’d think it would have happened after all these years. It hasn’t, and I don’t expect it to.
Someone will rightly make the point that mandatory typing can be very helpful in an IDE - its easier to find callers of methods, implementors, references to fields or classes, as well as refactoring (though, oddly, all these features originated in IDEs for dynamic languages - Smalltalk or Lisp; speculating why that is would make for another controversial post). This post isn’t really about static/dynamic typing - it’s about incrementality in the IDE.
Of course, mainstream IDEs annoy me for other reasons: the bloat, the slow startup, and most of all the B-52 bomber/Apollo space capsule style UI. That probably deserves another post.
In the meantime, I can go back to Vassili’s fabulous Hopscotch browsers and leave the mainstream to cope with all the docking bars, tabs and panes too small to print their name. You, dear reader, if you’re using a mainstream IDE, may not realize what you’re missing. To an extent, these things have to be experienced to be appreciated. Still I encourage you to demand better - demand true incremental development support, in whatever language you use. Because in the end, there are only two kinds of development - incremental, and excremental.
What I actually expected to do was to work on a Java IDE. Given my Smalltalk background, I was of course very much aware of how valuable a good IDE is for programmers. The Java IDE I had in mind never materialized. Management at the time thought this was an issue to be left to other vendors. If this seems a little strange today - well, it seemed strange back then too. In any case, the Java world has since learned that IDEs are very important and strategic.
That said, todays Java IDEs are still very different from what I envisioned based on my Smalltalk background.
Java IDEs have yet to fully embrace the idea of incremental development. Look in any such system, and you’ll find a button or menu labeled Build. The underlying idea is that a program is assembled from scratch every time you change it.
Of course, that is how the real world works, right? You find a broken window on the Empire State building, so you tear it down and rebuild it with the fixed window. If you're clever, you might be able to do it pretty fast. Ultimately, it doesn't scale.
The build button comes along with an obsession with files. In C and its ilk, the notion of files is part of the language, because of #include. Fortunately, Java did away with that legacy. Java programmers can think in terms of packages, independent of their representation on disk. Why spend time worrying about class paths and directory structures? What do these have to do with the structure of your program and the problem you’re trying to solve?
The only point where files are useful in this context is as a medium for sharing source code or distributing binary code. Files are genuinely useful for those purposes, and Smalltalk IDEs have generally gone overboard in the opposite direction; but I digress.
A consequence of the file/build oriented view is that the smallest unit of incremental change is the file - something that is often too big (if you ever notice the time it takes to compile a change, that’s too long) and moreover, not even a concept in the language.
More fundamentally, what’s being changed is a static, external representation of the program code; there is no support for changing the live process derived from the code so that it matches up with the code that describes it. It’s like having a set of blueprints for a building (the code in the file) which doesn’t match the building (the process generated from the code).
For example, once you add an instance variable to a class, what happens to all the existing instances on the heap? In Smalltalk, they all have the new instance variable. In Java - well, nothing happens.
In general, any change you make to the code should be reflected immediately in the entire environment. This implies a very powerful form of fix-and-continue debugging (I note in amazement that after all these years, Eclipse still doesn’t support even the most basic form of fix-and-continue).
All this is of course a very tall order for a language with a mandatory static type system.
I’m not aware of a JVM implementation that can begin to deal with class schema changes (that is, changing the shapes of objects because their class has lost or acquired fields). It’s not impossible, but it is hard.
Consider that removing a field requires invalidating any code that refers to it. In a language where fields are private, the amount of code to invalidate is nicely bounded to the class (good design decisions tend to simplify life). Public fields, apart from their nasty software engineering properties, add complexity to the underlying system.
This isn’t just a headache for the IDE. The VM has to provide support for changing the classes of existing instances. However, in the absence of VM support there all kinds of tricks one can play. If you compile all code yourself, you can ensure that no one accesses fields directly - everything goes through accessors. You can even rewrite imported binaries. With enough effort, I believe you can make it all work on an existing JVM with good JVMDI support.
Changing code in a method is supported by JVMDI (well, the JVMDI spec allows for supporting schema changes as well - it’s just that it isn’t required and no one ever implemented it). However, what happens if you change the signature of a method? Any number of existing callers may be invalid due to type errors. The IDE needs to tell you about this pretty much instantaneously, invalidating all these callers. Most of this worked in Trellis/Owl back in the late 80s. The presence of the byte code verifier means that this applies to binary code as well.
Achieving true incremental development is very hard. Still, given the amount of people working on Java, you’d think it would have happened after all these years. It hasn’t, and I don’t expect it to.
Someone will rightly make the point that mandatory typing can be very helpful in an IDE - its easier to find callers of methods, implementors, references to fields or classes, as well as refactoring (though, oddly, all these features originated in IDEs for dynamic languages - Smalltalk or Lisp; speculating why that is would make for another controversial post). This post isn’t really about static/dynamic typing - it’s about incrementality in the IDE.
Of course, mainstream IDEs annoy me for other reasons: the bloat, the slow startup, and most of all the B-52 bomber/Apollo space capsule style UI. That probably deserves another post.
In the meantime, I can go back to Vassili’s fabulous Hopscotch browsers and leave the mainstream to cope with all the docking bars, tabs and panes too small to print their name. You, dear reader, if you’re using a mainstream IDE, may not realize what you’re missing. To an extent, these things have to be experienced to be appreciated. Still I encourage you to demand better - demand true incremental development support, in whatever language you use. Because in the end, there are only two kinds of development - incremental, and excremental.
Tuesday, May 06, 2008
The Future of Newspeak
Several people have asked me when Newspeak will be released. Well, I still don’t know, but at least now I know it will be released. Cadence has generously agreed to make Newspeak available as open source software under the Apache 2.0 license.
We will be publishing a draft spec for Newspeak soon; I say draft because I expect Newspeak to continue to evolve substantially for the next year at least, and because the initial spec will necessarily be incomplete.
It will be a while before we are ready to make a proper public release of Newspeak. In the meantime, I’ve gathered some information on my personal web site. We plan to set up an official Newspeak web site in the near future.
We will be publishing a draft spec for Newspeak soon; I say draft because I expect Newspeak to continue to evolve substantially for the next year at least, and because the initial spec will necessarily be incomplete.
It will be a while before we are ready to make a proper public release of Newspeak. In the meantime, I’ve gathered some information on my personal web site. We plan to set up an official Newspeak web site in the near future.
Saturday, April 26, 2008
java'scrypt
Everyone is talking about cloud computing these days; I should add some vapor to the mist.
I began thinking seriously about the topic a bit after April fools day 2004, when gmail was released. I started using gmail shortly therefater. After about 30 minutes, I was convinced that web clients had a long way to go.
It is true that gmail showed the world that you could do far more with javascript in a browser than I or most other people had realized.
Javascript and Ajax have come a long way since then. For an impressive demonstration of what’s possible, see the Lively Kernel, a realization of John Maloney’s Morphic GUI ideas of Self and Squeak, in Javascript. It only works in Safari 3.0 and some advanced Firefox builds, but that situation will improve in time.
Javascript’s performance remains an issue; this will also improve dramatically in the foreseeable future. However, with all the talk about computing in the cloud, I think some caveats are in order.
Many real applications will need to be used offline, and so will need to store state on the client. They are NOT going to be pure server side web applications. Google has finally acknowledged as much with the introduction of Google Gears. Microsoft’s LiveMesh naturally emphasizes this even more.
I say naturally, because Microsoft has an interest in the personal computer, while Google has an interest in taking us to an updated version of X terminals and 1960’s time sharing.
Of course, there are other technologies in this space, like Adobe Air. Macromedia (now part of Adobe) saw this coming earlier than most, going back to at least 2003 with its Central project.
With all these pieces in place, we may finally have the underlying elements necessary to build good applications delivered through the web browser.
Why has this taken so long? In theory, Java was supposed to deliver all this over ten years ago. Java started as a client technology, and applets were supposed to do exactly what advanced Ajax applications do today, only better.
Of course, the problem was that Java clients behaved very poorly; rather than fix the client technology, Sun captured the lucrative enterprise business. To understand why Sun behaved that way, why it had to behave that way, read The Innovator’s Dilemma.
Maybe I’ll expand on that theme in another post.
The result of Java’s failure on the client was that the entire vision of rich network-enabled client applications was put on hold for a decade. It is now once again coming to the fore, but there are other languages in that space now, Javascript chief among them.
I’m not advocating writing clients in Javascript directly. Javascript is the assembly language of the internet platform (and the browser is the OS). It’s flexible enough to support almost anything on top of it, and poorly structured enough that humans shouldn’t be writing sizable applications in it.
I am not in favor of the attempts to make Javascript 2 be another Java either. Javascript’s importance stems from the existing version’s position in the browser, and from its flexibility. It should be kept simple. Javascript's value increases the more uniformly it is implemented across browsers. A new, complex language will take a long time to reach that point.
People should program in a variety of languages that suit them, and have these compiled to Javascript and HTML (GWT is an example of that, though not one I really like). One shouldn't have to deal with the hodgepodge of Javascript and HTML (broadly defined to include XML, CSS etc.) that constitute web programming today.
I don’t expect native clients to go away any time soon though. They will provide a better experience than the browser in many ways for quite a long time. The advantage of writing in a clean, high level language and platform is that it can be compiled to run either on the “WebOS” or on a native OS.
What one wants to see in such a platform is the ability to take advantage of the network in a deep way - for software delivery and update and for data synchronization. Which brings me back to my theme of objects as software services (see the video), which I’ve been preaching publicly since 2005 ( see my OOPSLA 2005 presentation).
One should be able to write an application once, and deploy it both to the web browser and natively to any major platform. In all those scenarios, one should be able to update the software and data on the fly, run it on- and offl-ine and and monitor it over the network continuously. And all this needs to be done in a way that preserves user’s security. This last bit is still a big challenge.
The technology to do this is becoming available, even though everything takes much longer than one expects. The vision has its root in research in the 1980s, continued in the 1990s with Java (and others, now largely forgotten, like General Magic's Telescript) and will be probably be realized in the 2010s, per Alan Kay’s 30 year rule.
I began thinking seriously about the topic a bit after April fools day 2004, when gmail was released. I started using gmail shortly therefater. After about 30 minutes, I was convinced that web clients had a long way to go.
It is true that gmail showed the world that you could do far more with javascript in a browser than I or most other people had realized.
Javascript and Ajax have come a long way since then. For an impressive demonstration of what’s possible, see the Lively Kernel, a realization of John Maloney’s Morphic GUI ideas of Self and Squeak, in Javascript. It only works in Safari 3.0 and some advanced Firefox builds, but that situation will improve in time.
Javascript’s performance remains an issue; this will also improve dramatically in the foreseeable future. However, with all the talk about computing in the cloud, I think some caveats are in order.
Many real applications will need to be used offline, and so will need to store state on the client. They are NOT going to be pure server side web applications. Google has finally acknowledged as much with the introduction of Google Gears. Microsoft’s LiveMesh naturally emphasizes this even more.
I say naturally, because Microsoft has an interest in the personal computer, while Google has an interest in taking us to an updated version of X terminals and 1960’s time sharing.
Of course, there are other technologies in this space, like Adobe Air. Macromedia (now part of Adobe) saw this coming earlier than most, going back to at least 2003 with its Central project.
With all these pieces in place, we may finally have the underlying elements necessary to build good applications delivered through the web browser.
Why has this taken so long? In theory, Java was supposed to deliver all this over ten years ago. Java started as a client technology, and applets were supposed to do exactly what advanced Ajax applications do today, only better.
Of course, the problem was that Java clients behaved very poorly; rather than fix the client technology, Sun captured the lucrative enterprise business. To understand why Sun behaved that way, why it had to behave that way, read The Innovator’s Dilemma.
Maybe I’ll expand on that theme in another post.
The result of Java’s failure on the client was that the entire vision of rich network-enabled client applications was put on hold for a decade. It is now once again coming to the fore, but there are other languages in that space now, Javascript chief among them.
I’m not advocating writing clients in Javascript directly. Javascript is the assembly language of the internet platform (and the browser is the OS). It’s flexible enough to support almost anything on top of it, and poorly structured enough that humans shouldn’t be writing sizable applications in it.
I am not in favor of the attempts to make Javascript 2 be another Java either. Javascript’s importance stems from the existing version’s position in the browser, and from its flexibility. It should be kept simple. Javascript's value increases the more uniformly it is implemented across browsers. A new, complex language will take a long time to reach that point.
People should program in a variety of languages that suit them, and have these compiled to Javascript and HTML (GWT is an example of that, though not one I really like). One shouldn't have to deal with the hodgepodge of Javascript and HTML (broadly defined to include XML, CSS etc.) that constitute web programming today.
I don’t expect native clients to go away any time soon though. They will provide a better experience than the browser in many ways for quite a long time. The advantage of writing in a clean, high level language and platform is that it can be compiled to run either on the “WebOS” or on a native OS.
What one wants to see in such a platform is the ability to take advantage of the network in a deep way - for software delivery and update and for data synchronization. Which brings me back to my theme of objects as software services (see the video), which I’ve been preaching publicly since 2005 ( see my OOPSLA 2005 presentation).
One should be able to write an application once, and deploy it both to the web browser and natively to any major platform. In all those scenarios, one should be able to update the software and data on the fly, run it on- and offl-ine and and monitor it over the network continuously. And all this needs to be done in a way that preserves user’s security. This last bit is still a big challenge.
The technology to do this is becoming available, even though everything takes much longer than one expects. The vision has its root in research in the 1980s, continued in the 1990s with Java (and others, now largely forgotten, like General Magic's Telescript) and will be probably be realized in the 2010s, per Alan Kay’s 30 year rule.
Sunday, March 23, 2008
Monkey Patching
Earlier this month I spoke at the International Computer Science Festival in Krakow. Krakow is a beautiful city with several universities, and it is becoming a high tech center, with branches of companies like IBM and Google. The CS festival draws well over a thousand participants; the whole thing is organized by students. While much of the program was in Polish, there were quite a few talks in English.
Among these was Chad Fowler’s talk on Ruby. Chad is a very good speaker, who did an excellent job of conveying the sense of working in a dynamic language like Ruby. Almost everything he said would apply to Smalltalk as well.
One of the points that came up was the custom, prevalent in Ruby and in Smalltalk, of extending existing classes with new methods in the service of some other application or library. Such methods are often referred to as extension methods in Smalltalk, and the practice is supported by tools such as the Monticello source control system.
As an example, I’ll use my parser combinator library, which I’ve described in previous posts. To define a production for an if statement, you might write:
if:: tokenFromSymbol: #if.
then:: tokenFromSymbol: #then.
ifStat:: if, expression, then, statement.
assuming that productions for expression and statement already exist. The purpose of the rules if and then is to produce a tokenizing parser that accepts the symbols #if and #then respectively. It might be nicer to just write:
ifStat:: #if, expression, #then, statement.
and have the system figure out that, in this context, you want to denote a parser for a symbol by the symbol directly, much as you would when writing the BNF.
One way of achieving this would be to actually go and add the necessary methods to the class Symbol, so that symbols could behave like parsers. I know otherwise intelligent people who are prepared to argue for this approach. As I said, Smalltalkers would call these additions extension methods, but I find the more informal term monkey patching conveys a better intuition.
Typically, one wants to deliver a set of such methods as a unit, to be installed when a certain class or library gets loaded. So these changes are often provided as a patch that is applied dynamically. Not a problem in Smalltalk or Ruby or Python (though I gathered from the Pythoners in Krakow that they, to their credit, frown on the practice).
Apparently, there is a need to explain why monkey patching is a really bad idea. For starters, the methods in one monkey’s patch might conflict with those in some other monkey’s patch. In our example, the sequencing operator for parsers conflicts with that for symbols.
A mere flesh wound, says our programming primate: I usually don’t get conflicts, so I’ll pretend they won’t happen. The thing is, as thing scale up, rare occurrences get more frequent, and the costs can be very high.
Another problem is API bloat. You can see this in Squeak images, where a lot of monkeying about has taken place over the years. Classes like Object and String are polluted with dozens of methods contributed by enterprising individuals who felt that their favorite convenience method is something the whole world needs to benefit from.
Even in your own code, one needs to exercise restraint lest your API becomes obese with convenience methods. Big APIs eat up memory for both people and machinery, reducing responsiveness as well as learnability.
Then there is the small matter of security. If you are free to patch the definition of a class like String (typically on the fly when their code gets loaded), what’s to stop malicious macaques from replacing critical methods with really damaging stuff?
The counter argument is that in many cases (though not in this example), the patch is designed to avoid the use of typecase/switch/instance-of constructs, which bring their own set of evils to the table.
Extractors are a new approach to pattern matching developed by Martin Odersky for Scala. They overcome the usual difficulty with pattern matching, which is that it violates encapsulation by exposing the implementation type of data, just like instance-of. It may be part of the answer here as well.
However, many monkey patches are motivated by a desire for syntactic sugar, as the example shows. Extractors won’t help here.
A variety of language constructs have been devised to deal with this and related situations. Class boxes and selector namespaces in Smalltalk dialects, context oriented programming in Lisp and Smalltalk, static extension methods in C# and even Haskell type classes are related. These mechanisms don’t all provide the same functionality of course. I confess that I find none of them attractive. Each comes at a price that is too high for what it provides.
For example, C# extension methods rely on mandatory typing. Furthermore, they would not address the example above, because we need the literal symbols we use in the grammar to behave like parsers when passed into the parser combinator library code, not just in the lexical scope of the grammar.
Haskell type classes are much better. They would work for this problem (and many others), but also rely crucially on mandatory typing.
Class boxes are dynamic, but again only effect the immediate lexical scope. The same is true of simple formulations of selector namespaces. Richer versions let you import the desired selectors elsewhere, but I find this gets rather baroque. I'm not sure how COP meshes with security; so far it seems too complex for me to consider.
I’ve contemplated a change to the Newspeak semantics that would accommodate the above example, but it hasn’t been implemented, and I have mixed feelings about it. If a literal like #if is interpreted as an invocation of a factory method on Symbol, then we can override Symbol so that it supports the parser combinators. This only effects symbols created in a given scope, but isn’t just syntactic sugar like the C# extension methods suggested above.
Of course, this can be horribly abused; one shudders to think what a band of baboons might make of the freedom to redefine the language’s literals. On the other hand, used judiciously, it is great for supporting domain specific languages.
So far, I have no firm conclusions about how to best address the problems monkey patching is trying to solve. I don’t deny that it is expedient and tempting. Much of the appeal of dynamic languages is of course the freedom to do such things. The contrast with a language like Java is instructive. Adding a method to String is pretty much impossible. One has to sacrifice one’s first-born to the gods of the JCP and wait seven years for them to decide whether to add the method or not. I’m not endorsing that model either: I know it only too well.
Regardless, given my flattering portrayals of primate practices, you may deduce that my main comment on monkey patching is “just say no”. The problems it induces far outweigh its benefits. If you feel tempted, think hard about design alternatives. One can do better.
Among these was Chad Fowler’s talk on Ruby. Chad is a very good speaker, who did an excellent job of conveying the sense of working in a dynamic language like Ruby. Almost everything he said would apply to Smalltalk as well.
One of the points that came up was the custom, prevalent in Ruby and in Smalltalk, of extending existing classes with new methods in the service of some other application or library. Such methods are often referred to as extension methods in Smalltalk, and the practice is supported by tools such as the Monticello source control system.
As an example, I’ll use my parser combinator library, which I’ve described in previous posts. To define a production for an if statement, you might write:
if:: tokenFromSymbol: #if.
then:: tokenFromSymbol: #then.
ifStat:: if, expression, then, statement.
assuming that productions for expression and statement already exist. The purpose of the rules if and then is to produce a tokenizing parser that accepts the symbols #if and #then respectively. It might be nicer to just write:
ifStat:: #if, expression, #then, statement.
and have the system figure out that, in this context, you want to denote a parser for a symbol by the symbol directly, much as you would when writing the BNF.
One way of achieving this would be to actually go and add the necessary methods to the class Symbol, so that symbols could behave like parsers. I know otherwise intelligent people who are prepared to argue for this approach. As I said, Smalltalkers would call these additions extension methods, but I find the more informal term monkey patching conveys a better intuition.
Typically, one wants to deliver a set of such methods as a unit, to be installed when a certain class or library gets loaded. So these changes are often provided as a patch that is applied dynamically. Not a problem in Smalltalk or Ruby or Python (though I gathered from the Pythoners in Krakow that they, to their credit, frown on the practice).
Apparently, there is a need to explain why monkey patching is a really bad idea. For starters, the methods in one monkey’s patch might conflict with those in some other monkey’s patch. In our example, the sequencing operator for parsers conflicts with that for symbols.
A mere flesh wound, says our programming primate: I usually don’t get conflicts, so I’ll pretend they won’t happen. The thing is, as thing scale up, rare occurrences get more frequent, and the costs can be very high.
Another problem is API bloat. You can see this in Squeak images, where a lot of monkeying about has taken place over the years. Classes like Object and String are polluted with dozens of methods contributed by enterprising individuals who felt that their favorite convenience method is something the whole world needs to benefit from.
Even in your own code, one needs to exercise restraint lest your API becomes obese with convenience methods. Big APIs eat up memory for both people and machinery, reducing responsiveness as well as learnability.
Then there is the small matter of security. If you are free to patch the definition of a class like String (typically on the fly when their code gets loaded), what’s to stop malicious macaques from replacing critical methods with really damaging stuff?
The counter argument is that in many cases (though not in this example), the patch is designed to avoid the use of typecase/switch/instance-of constructs, which bring their own set of evils to the table.
Extractors are a new approach to pattern matching developed by Martin Odersky for Scala. They overcome the usual difficulty with pattern matching, which is that it violates encapsulation by exposing the implementation type of data, just like instance-of. It may be part of the answer here as well.
However, many monkey patches are motivated by a desire for syntactic sugar, as the example shows. Extractors won’t help here.
A variety of language constructs have been devised to deal with this and related situations. Class boxes and selector namespaces in Smalltalk dialects, context oriented programming in Lisp and Smalltalk, static extension methods in C# and even Haskell type classes are related. These mechanisms don’t all provide the same functionality of course. I confess that I find none of them attractive. Each comes at a price that is too high for what it provides.
For example, C# extension methods rely on mandatory typing. Furthermore, they would not address the example above, because we need the literal symbols we use in the grammar to behave like parsers when passed into the parser combinator library code, not just in the lexical scope of the grammar.
Haskell type classes are much better. They would work for this problem (and many others), but also rely crucially on mandatory typing.
Class boxes are dynamic, but again only effect the immediate lexical scope. The same is true of simple formulations of selector namespaces. Richer versions let you import the desired selectors elsewhere, but I find this gets rather baroque. I'm not sure how COP meshes with security; so far it seems too complex for me to consider.
I’ve contemplated a change to the Newspeak semantics that would accommodate the above example, but it hasn’t been implemented, and I have mixed feelings about it. If a literal like #if is interpreted as an invocation of a factory method on Symbol, then we can override Symbol so that it supports the parser combinators. This only effects symbols created in a given scope, but isn’t just syntactic sugar like the C# extension methods suggested above.
Of course, this can be horribly abused; one shudders to think what a band of baboons might make of the freedom to redefine the language’s literals. On the other hand, used judiciously, it is great for supporting domain specific languages.
So far, I have no firm conclusions about how to best address the problems monkey patching is trying to solve. I don’t deny that it is expedient and tempting. Much of the appeal of dynamic languages is of course the freedom to do such things. The contrast with a language like Java is instructive. Adding a method to String is pretty much impossible. One has to sacrifice one’s first-born to the gods of the JCP and wait seven years for them to decide whether to add the method or not. I’m not endorsing that model either: I know it only too well.
Regardless, given my flattering portrayals of primate practices, you may deduce that my main comment on monkey patching is “just say no”. The problems it induces far outweigh its benefits. If you feel tempted, think hard about design alternatives. One can do better.
Sunday, February 17, 2008
Cutting out Static
Most imperative languages have some notion of static variable. This is unfortunate, since static variables have many disadvantages. I have argued against static state for quite a few years (at least since the dawn of the millennium), and in Newspeak, I’m finally able to eradicate it entirely. Why is static state so bad, you ask?
Static variables are bad for security. See the E literature for extensive discussion on this topic. The key idea is that static state represents an ambient capability to do things to your system, that may be taken advantage of by evildoers.
Static variables are bad for distribution. Static state needs to either be replicated and sync’ed across all nodes of a distributed system, or kept on a central node accessible by all others, or some compromise between the former and the latter. This is all difficult/expensive/unreliable.
Static variables are bad for re-entrancy. Code that accesses such state is not re-entrant. It is all too easy to produce such code. Case in point: javac. Originally conceived as a batch compiler, javac had to undergo extensive reconstructive surgery to make it suitable for use in IDEs. A major problem was that one could not create multiple instances of the compiler to be used by different parts of an IDE, because javac had significant static state. In contrast, the code in a Newspeak module definition is always re-entrant, which makes it easy to deploy multiple versions of a module definition side-by-side, for example.
Static variables are bad for memory management. This state has to be handed specially by implementations, complicating garbage collection. The woeful tale of class unloading in Java revolves around this problem. Early JVMs lost application’s static state when trying to unload classes. Even though the rules for class unloading were already implicit in the specification, I had to add a section to the JLS to state them explicitly, so overzealous implementors wouldn’t throw away static application state that was not entirely obvious.
Static variables are bad for for startup time. They encourage excess initialization up front. Not to mention the complexities that static initialization engenders: it can deadlock, applications can see uninitialized state, and unless you have a really smart runtime, you find it hard to compile efficiently (because you need to test if things are initialized on every use).
Static variables are bad for for concurrency. Of course, any shared state is bad for concurrency, but static state is one more subtle time bomb that can catch you by surprise.
Given all these downsides, surely there must be some significant upside, something to trade off against the host of evils mentioned above? Well, not really. It’s just a mistake, hallowed by long tradition. Which is why Newspeak has dispensed with it.
It may seem like you need static state, somewhere to start things off, but you don’t. You start off by creating an object, and you keep your state in that object and in objects it references. In Newspeak, those objects are modules.
Newspeak isn’t the only language to eliminate static state. E has also done so, out of concern for security. And so has Scala, though its close cohabitation with Java means Scala’s purity is easily violated. The bottom line, though, should be clear. Static state will disappear from modern programming languages, and should be eliminated from modern programming practice.
Static variables are bad for security. See the E literature for extensive discussion on this topic. The key idea is that static state represents an ambient capability to do things to your system, that may be taken advantage of by evildoers.
Static variables are bad for distribution. Static state needs to either be replicated and sync’ed across all nodes of a distributed system, or kept on a central node accessible by all others, or some compromise between the former and the latter. This is all difficult/expensive/unreliable.
Static variables are bad for re-entrancy. Code that accesses such state is not re-entrant. It is all too easy to produce such code. Case in point: javac. Originally conceived as a batch compiler, javac had to undergo extensive reconstructive surgery to make it suitable for use in IDEs. A major problem was that one could not create multiple instances of the compiler to be used by different parts of an IDE, because javac had significant static state. In contrast, the code in a Newspeak module definition is always re-entrant, which makes it easy to deploy multiple versions of a module definition side-by-side, for example.
Static variables are bad for memory management. This state has to be handed specially by implementations, complicating garbage collection. The woeful tale of class unloading in Java revolves around this problem. Early JVMs lost application’s static state when trying to unload classes. Even though the rules for class unloading were already implicit in the specification, I had to add a section to the JLS to state them explicitly, so overzealous implementors wouldn’t throw away static application state that was not entirely obvious.
Static variables are bad for for startup time. They encourage excess initialization up front. Not to mention the complexities that static initialization engenders: it can deadlock, applications can see uninitialized state, and unless you have a really smart runtime, you find it hard to compile efficiently (because you need to test if things are initialized on every use).
Static variables are bad for for concurrency. Of course, any shared state is bad for concurrency, but static state is one more subtle time bomb that can catch you by surprise.
Given all these downsides, surely there must be some significant upside, something to trade off against the host of evils mentioned above? Well, not really. It’s just a mistake, hallowed by long tradition. Which is why Newspeak has dispensed with it.
It may seem like you need static state, somewhere to start things off, but you don’t. You start off by creating an object, and you keep your state in that object and in objects it references. In Newspeak, those objects are modules.
Newspeak isn’t the only language to eliminate static state. E has also done so, out of concern for security. And so has Scala, though its close cohabitation with Java means Scala’s purity is easily violated. The bottom line, though, should be clear. Static state will disappear from modern programming languages, and should be eliminated from modern programming practice.