Source control is an area of software development in need of reform. There is need for a clean, clear semantic model. To the extent that existing source control systems have some sort of model, each system is different. Each has its own terminology, usually entangled with the mechanics of file systems and directories. As with IDEs, the use of files and text has spread in this domain because it is a lowest common denominator.
Semi-tangent: Well, almost a common denominator; it doesn’t cover Smalltalk, but this can be fairly viewed as Smalltalk’s fault, not source control’s.
As with IDEs, the tie to files is unfortunate because low level abstractions like text files and file systems are completely extraneous to the problem at hand.
The major advantage of the text file based approach is that, rather than invent a source control system for every language, we can build one system that assumes source code consists of text files and go from there. A big disadvantage is that such a system has no understanding of the source code. It doesn’t understand the structure of a program - be it functions or classes or prototypes or procedures or what-have-you.
The mainstream approach also has another advantage: it can integrate artifacts from multiple languages. And another: we can go even lower than text files, and just consider files, so we can manage binaries and resources as well. In general, while we would like programming language-specific understanding, we also want to deal with multiple languages, and with artifacts that go beyond source code.
Again, we return to the lack of a semantic model: not just for understanding the sources, but for the language-independent part of the system. What are versions, what are differences, what are repositories exactly? The answers differ from system to system, and are hard to disentangle from the mechanics of files and directories.
People have addressed parts of the problem, but I don’t know of a completely satisfactory solution. For example DARCS has a model of differences that is rather interesting. However, it doesn’t tackle other issues, and the experience of the Haskell community using it has been mixed at best.
In the Smalltalk world, Monticello (and more recently, Metacello) provide a language aware source code management (SCM) system. I’ve explained some of the problems with that approach above. We tried to mitigate these somewhat in the Hopscotch IDE, where we mated Monticello with svn and a new GUI. The idea was to use a mainstream standard tool with a language specific front end. No need to reinvent the entire wheel, only select parts. That too has been a mixed experience.
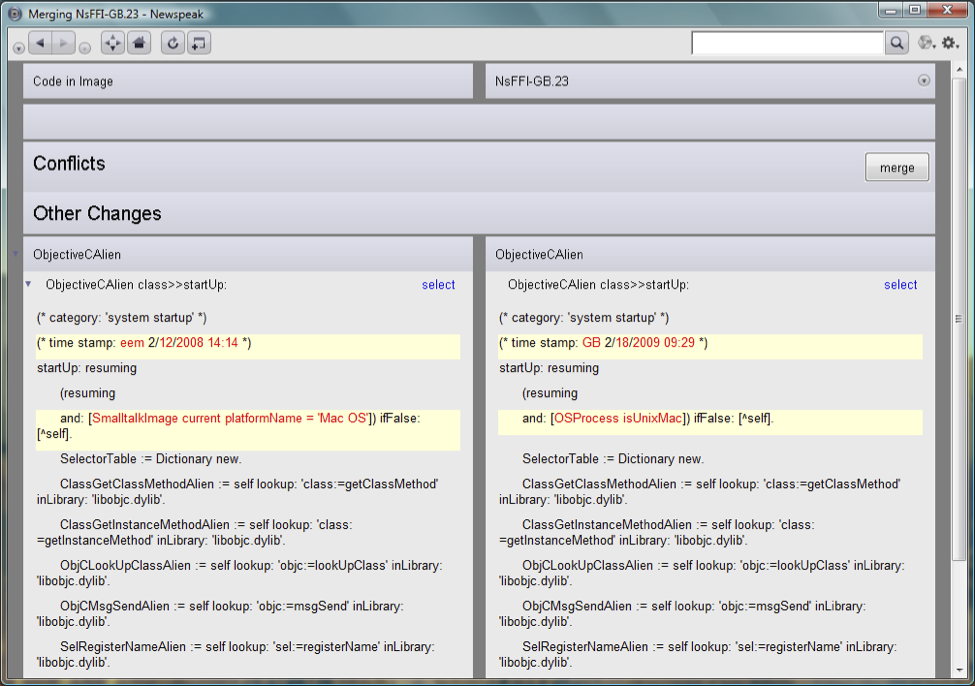
On the one hand, we’ve enjoyed a nice GUI. For example, the changes presenter displays semantically meaningful diffs - the system tells us what classes have changed, and what methods within them, resorting to textual diffing only within methods. The diff is displayed side-by-side in the traditional manner; the key difference is that we get individual diffs for each unit of program structure. For example, if you’ve changed two methods in a class with 30 methods, you’ll only see the diffs for those two methods.
In the screenshot, we can see that the startup: method in the class ObjectiveCAlien is the only thing that has changed.
On the other hand, the cost and effort of rolling one’s own VCS tool is considerable even when it is done on top of a standard VCS that does the heavy lifting. Because of this, we have not yet been able to realize all of the advantages we could from such a system. We could potentially show you time-machine like views of individual classes or methods, since concepts like versions and history apply to these entities.
The system shown above is based on svn, and svn doesn’t support distributed development well; this became an acute problem when the project went open source.
So - do we need to build variants of such a system for other SCMs? Given N languages and M SCMs, you get N x M systems. Unattractive. One can see why people have stuck with the standard tools.
If we had a uniform abstraction of an SCM then we could implement the abstraction once on top of every real SCM we wanted to use. We could then implement language specific functionality on top of the abstract model. Now you get N+M pieces you need to build.
This is what Matthias Kleine set out to do in his masters thesis. The result is Pur, which defines a model that is general enough to describe several of the leading SCMs (mercurial, git, svn). MemoryHole, a Newspeak specific version control tool, has been built on top of Pur using a binding to mercurial. Since August 2011, we’ve been using MemoryHole instead of the svn-based tools. One nice thing is that MemoryHole can work with git as well, and potentially even with old-fashioned svn. Here’s a screenshot of MemoryHole in action:

We see two columns listing top level classes that differ between the running system and a repository. Each class is presented as a tree view of parts that differ. At the level of individual methods, we revert to a text diff. The configDo: method of class VCSMercurialBackedProvider`Backend`LocalRepository`Commands`NonCachingCommand is expanded to show what’s changed (a flush was added, highlighted in red).
Tangent: We see 4 levels of class nesting here, which is as deep as I’ve seen in any Newspeak program.
MemoryHole gives us a distributed source control GUI application that is language-aware, but can work with differing standard SCMs. And of course, it is written in Newspeak so it is modular and extensible.
Keeping a language specific VCS running in sync with an evolving language was a problem in the early days of Newspeak. This is again part of the price one pays for dedicated language support. When the language is stable I think it is well worth the cost, just like any other language-aware tooling, be it an Eclipse plugin, an emacs mode, or something better.
Indeed, the situation is analogous to what happens with text editors versus IDEs. The text editor is a lowest common denominator: the same tool can handle any programming language, and many other things as well. The IDE needs to be tuned extensively to each and every language, but in the end can give you a better experience. It took a long time for people to appreciate IDEs with their language specific support for editing, and to this day not everyone does. I imagine we’ll see a similar evolution in the area of source control.
Most intriguing to me is the connection to the general problem of synchronizing data, including programs (being a special case of data), across the network. In the past, I’ve discussed the idea of objects as software services and full-service computing. I see source control as just a special case of that. Something to discuss another time.
The story doesn’t ned here of course. There is a need for mathematical models and theory, and bindings of many languages to many SCMs. In general, more researchers should look at source control; no doubt they will have their own ideas. I hope we move the world a little bit forward, beyond files and text diffs.
18 comments:
Aren't you just looking for a language aware diff tool? Most VCS will let you use an external diff tool. So, you can leverage existing functionality, but make a cooler diff visualization. I don't really see this as rethinking version control from the ground up. Maybe I'm missing something.
I just held a "lecture" on SCM and one of my "points" is the lack of semantics, so very timely article.
A few years back I wrote Deltastreams (well, just the Delta part) for Squeak - improved Changesets. Deltas take a step further on capturing the semantics behind the actual modifications.
See http://wiki.squeak.org/squeak/DeltaStreams
regards, Göran Krampe
Ones Self:
Language aware diff is part of what I want. Perhaps the post focuses more on that in the interest of brevity.
But I also want a real semantics of version control, a theory that describes what, precisely, is a version, what are its parents, what is a history, what is repository etc. All these concepts apply to any kind of datum, including language constructs. Notions of merging and/or synchronization apply beyond source control.
MemoryHole is a step on that path, and I can see us going further. The area needs work, both theoretical and practical.
Hi Goran,
Thanks for the pointer.
Hi Gilad!, remember that VASmalltalk has ENVY and ENVY has existed for many many years and in my opinion, is the best SCM tools that have ever existed, not only for Smalltalk.
So saying that Smalltalk has not SCM is not fear really :-)
Sorry, I meant "really fair" not "fear" :-)
Hi Hernan,
Nice to hear from you! Sorry I forgot about Envy. But the point remains - we need a principled approach, a theory.
Hi Gilad. Are you aware the work Veronica Isabel Uquillas Gomez is doing? Maybe you can get something from there:
http://soft.vub.ac.be/~vuquilla/Site/Tools.html
From what I can see it touches some of the topics you mention.
Cheers
Hi Mariano,
Thanks for the pointer. I took a quick look - the emphasis seems more on visualization, but I'll try and read the papers and see.
From what I can see there is an emphasis in visualizations but the most important one is how the tool can help in the "merge" process and to understand what a certain change means.
A theory like: Managing design data: the five dimensions of CAD frameworks, configuration management, and product data management.
van den Hamer, P. Lepoeter, K.
Philips Res., Eindhoven?
Darcs is based on a theory of patches based on commutative operators. However, David Durand's dissertation "Palimpsest: Change-Oriented Concurrency Control for the Support of Collaborative Applications", has a much better theory of change-oriented as opposed to version-oriented change control. It's no longer online, alas; this table, which is my work not Durand's, seems to be the only surviving version. I'll try to write a companion piece explaining Palimpsest's unique method of addressing points and ranges of a document.
John,
Thanks for the reference. Hopefully, I'll get around to locating it.
I've thought for a long time that Source Control should be more language aware. Being able to source control at different grains, such as single methods, classes and modules would be very useful.
Further, there are parallels with Undo/Redo mechanisms. For example a single refactoring operation may touch various parts of a project - moving a method between classes for example may affect not just the two classes involved but also their clients. To the user this appears as a single operation.
It would be nice if SCM's could cope with these kind of things too.
Hi there Gilad.
Thanks for writing this article, I love the idea of using the current best of breed SCMs to do some of the heavy lifting and getting more value from structure awareness at the language level.
One question, and one comment:
1. Question: Why have you chosen to "At the level of individual methods, we revert to a text diff."?
It seems to me that Newspeak (or many other languages) still have syntactical or semantic structure within methods.
These structures are usually not made first class citizens at the UI or IDE level in the way an object, class, module, trait or any such higher level structures are supported by menus, browser layouts etc. (perhaps because code within a method changes too often and too fast to make it worth the effort... although there are syntax-driven editors I hear... and EMACS modes)
But anyway, when your focus changes from interactive code editing to SCM, it may be that these structures become valuable and should be considered?
2. Comment: I would love to see Göran Krampe ideas of capturing/managing change "intents", i.e. a defined taxonomy of changes mixed with your ideas: we would have "structured changes" applied to "structured contents", instead of classic current SCM tools low level "text changes" to "text files" or low level "text or object changes" to structured objects (MemoryHole ?).
Hi Francois,
Regarding your question. At one point, many years ago, structured editing was a hot topic. It is fair to say that it failed, mostly for the reasons you suggest: it is in fact too awkward in practice. Syntax coloring, name completion etc. do help however and are widely adopted.
Thanks for sharing, nice post! Post really provice useful information!
Giaonhan247 chuyên dịch vụ vận chuyển hàng đi mỹ cũng như dịch vụ ship hàng mỹ từ dịch vụ nhận mua hộ hàng mỹ từ trang ebay vn cùng với dịch vụ mua hàng amazon về VN uy tín, giá rẻ.
Some 10 years later, I noticed John Cowan's comment about my dissertation. It is online (as a test document on a test site): https://david.hub.agilepdf.com/Palimpsest_Change_oriented_Concurrency_Control_for_Collaborative_Application-- in case it is still of interest to anyone.
I've noticed that nowadays what I was doing is called a Commutative Replicated Datatype, or CRDT. I missed the boat, stopping my academic aspirations just shortly before the time people were getting interested in something I'd started to become tired of talking about.
Post a Comment